Seminars about artificial intelligence
AI Agora is an initiative from the Department of Information Science and Media Studies, and constitutes a lecture and discussion series about artificial intelligence in theory and as applied science. AI Agora presents international guests as well as local speakers.
Upcoming seminars
Passed seminars
Martha Larson: AI vs. Our Eye: New Perspectives on Adversarial Images – 10 March 13.15–14.30
Image: Fabrizio Falchi
Ambra Demontis: Adversarial Machine Learning @ 18 Nov 14:15-15:45

Tarek R. Besold: Symbols, Networks, Explanations: A Complicated Ménage à Trois
Sonja Smets: Computing Social Behavior @ 27 Aug 15:00-16:00
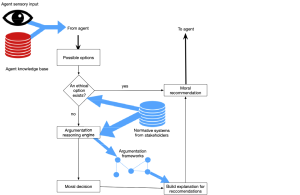
Marija Slavkovik: The Jiminy Advisor: Moral Agreements Among Stakeholders Based on Norms and Argumentation
Ana Ozaki: Knowledge Graphs: Facts and Figures
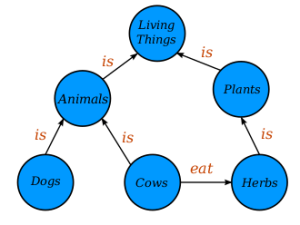
Pablo Gervás Gómes-Navarro: Modelling How People Build Stories from Observed Facts
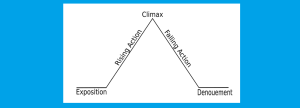
Dietmar Jannach: Session-based Recommendation: Challenges and Recent Advances
Pekka Parviainen: Introduction to Bayesian networks – the backbone of probabilistic modelling
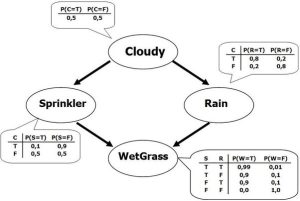
Enrico Motta: Hybrid AI: Integrating large scale data analysis with semantic technologies

Bjørnar Tessem: Artificial Intelligence: more than self-driving cars and face recognition
Gunnar Tufte: Maverick Machines: from Self-organising Matter to Thinking machines

Raffaella Bernardi: An old Artificial Intelligence dream that comes true: Merging language and vision modalities
Giovambattista Ianni: Intelligence in Video Games – From Pacman to the Angry Birds AI Competition Experience

Frank Dignum: TAIGA: Transdisciplinary AI for the Good of Al

Reza Arghandeh: AI in Space to Watch Storm Mess: How AI and Computer Vision come together to digest satellite images @ 4 October 14:15-16:00
Geraint A. Wiggins: The Scientific and Computational Study of Creativity @ 1 November 14:15-16
Jonas Ivarsson: Understanding Trust and Conversational Agents @ 1 November 13:15-14

Kerstin Bach: AI in Healthcare: An Interdisciplinary Journey @ 23 Nov 2.15-15.30

What is AI Agora?
In 1956 in Dartmouth, New Hamsphire, a group of scientists met up for discussions on how computers can be made more intelligent, and coined the term artificial intelligence (AI). Since then AI has been considered a part of computer science. It has had its ups and downs, with optimism in the 60-ies and 80-ies and less interest in other decades. Today AI is again a top topic both as a science and in the public.
At the University of Bergen, researchers at the Department of Information Science and Media Studies have worked in the field for several decades. An agora is a Greek term for a meeting place where people discuss public matters (and also a market place). Thus, the AI Agora is an initiative from the Department of Information Science and Media Studies, and constitutes a lecture and discussion series about artificial intelligence in theory and as applied science. AI Agora presents international guests as well as local speakers.